

コンピュータシステム(3)
システム構成
システム構成
集中処理と分散処理
集中処理
1台のコンピュータ(ホストコンピュータ)ですべての処理を行う形態のこと
(例:オンラインシステム)
|
●1台で管理するため、設備や人員を集中できる ●運用管理やセキュリティ管理、保守が行いやすい ●処理をしているコンピュータが故障するとシステム全体が停止する |
分離処理
ネットワーク上の複数のコンピュータを使い、処理を分散して行う形態
(例:クライアントシステム)
|
●機能の拡張が用意 ●1台のコンピュータが停止してもシステム全体は停止しない ●複数のコンピュータを使用する為、運用管理、セキュリティ管理、保守が複雑 ●システムに異常が発生した場合、原因の特定に時間を要するケースも |
 水平分散
水平分散
すべてのコンピュータが対等の立場でネットワークにつながっているシステム(ピアツーピア型)
垂直分散
コンピュータを階層的に結び付けて機能を分散させる処理形態(クライアントサーバシステム)
 ピアツーピア
ピアツーピア
ネットワークを構成するシステム形態。ネットワークに接続されたコンピュータを役割分担せず、お互いに対等な関係で接続させているため、サーバとクライアントの区別がない
インデックスサーバを持つHybrid P2Pとインデックスサーバを持たないPure P2Pに分類される
フラッディング
スイッチングハブにおいて、LANスイッチが受信したMACフレームをほかの全ポートに送り出す中継方法のこと。アドレス・テーブルの中にあて先MACアドレスが見つからないときや,ブロードキャスト・フレームを中継するときに実行する。ネットワークで接続された端末(隣接したノード)に対して、水があふれてまわりのノードにパケットを洪水のようにデータを流す
グリッドコンピューティング
ネットワークを介して複数のコンピュータを結ぶことで仮想的に高性能コンピュータをつくり、利用者はそこから必要なだけ処理能力や記憶容量を取り出して使うシステム。 複数のコンピュータに並列処理を行わせることで、一台一台の性能は低くとも高速に大量の処理を実行できるようになる。ビジネス利用や学術研究など、多くの可能性が模索され、実現に向けてさまざまな試みが行われている。
ネットワーク透過性
分散システムでの透過性とは、分散された構成をユーザから隠し、あたかも集中型システムであるかのように見せること
| 規模透過性 | OSやApplicationの構成に影響を与えることなくシステムの規模を変更できる |
|---|---|
| 位置透過性 | ユーザやリソースの配置を意識させない |
| アクセス透過性 | データの位置の遠近を意識させることなくアクセスできる |
| 並行透過性 | 複数のユーザが1つのリソースを共有して使用時、ユーザに競合状態を気づかせない |
| 同時実行透過性 | 複数のユーザや応用プログラムが同じデータを同時に更新できる |
| 複製透過性 | ユーザが意識することなく、複製を作成、利用できる |
| 移動透過性 | ユーザが意識することなく、装置や位置を変更できる |
| 故障透過性 | ネットワークやシステムに故障が発生しても、接続使用可能 |
| 障害透過性 | ネットワークやシステム障害が発生しても、代替手段によって継続使用可能 |
| 性能透過性 | システム構成の変更が性能に影響を与えない |
リアルタイム処理
トランザクションの発生と同時に処理を行う方式。即時性が要求され、レスポンスタイム(要求時間)に強い制約がある
クライアントサーバシステム
分散処理システムの一つ、サービスを提供する専用のコンピュータ(サーバ)と、そのサービスを要求するコンピュータ(クライアント)に分けてシステムを構築する方式
2層アーキテクチャ
従来の一般的なクライアントサーバシステムのこと。各クライアントから直接データベースへアクセスする。また、クライアント側からデータベースサーバのストアドプロシージャを利用できるので、クライアントとサーバ間のデータ転送量を抑えることが可能
ストアドプロシージャ
データベースに関する一連の処理をひとつのプログラムにまとめてデータベース管理システムに保存したもの。クライアント側から呼び出すことで実行可能。クライアント側からSQL文を一文ずつ送信して実行するより処理命令の送信時間を短縮⇒処理時間の短縮
3層クライアントサーバシステム
「プレゼンテーション層」「ファンクション層(アプリケーション層)」「データベースアクセス層」の3層に分割して構築したシステム
| 階層 | 論理 | 機能 | |
|---|---|---|---|
| 第1層 | プレゼンテーション層 | ユーザインタフェース部分 | クライアント |
| 第2層 | ファンクション層 | データ加工処理部分 | アプリケーションサーバ |
| 第3層 | データベースアクセス層 | データベースアクセス部分 | データベースサーバ |
クライアントとサーバ間のデータ通信量が少ないので、低速な低速な回線使用やクライアントの台数が多い場合でも対応速度が落ちにくい。処理件数の増加に対し、アプリケーションサーバなどの増強など、局所的な対応が可能に。開発効率の面では、アプリケーションを機能的に3モジュールに分離することで、仕様の変更操作が容易になり、各モジュールを並行して開発すれば、生産性も向上する。システム保守に関する作業負荷が減る
サーバの仮想化
●資源の運用管理が簡易
●物理的な資源利用率は高い
●オーバヘッドによる負荷が高い(制御などによる処理が増加するから)
RPC(Remote Procedure Call:遠隔手続呼出し)
自分のコンピュータから、他のコンピュータ上にあるプログラムを呼び出せるようにする機能
高信頼性システムの構成
コンピュータシステムの信頼性を向上させるには、故障しない(しにくい)製品やん部品を使用する方法と、並列度を高めて万一の場合に備える方法がある
信頼性向上の技術
信頼性を向上させるためのシステム構成や信頼性設計として、以下のものがある
| フォールトトレラント | システムの多重化などにより、障害が発生した場合にも他のシステムで処理を実行できるようにしておくこと |
|---|---|
| フォールトアボイダンス | 高品質・高信頼性の部品や素子を使用したり、故障の生じにくい設計や構造を採用したりすることで、システム全体での故障を回避しようとする考え方 |
| フェールソフト | ハードウェアやソフトウェアに障害が発生した場合、機能を低下させてでも、正常な部分を利用して運用を続行しようとする考え方 |
| フォールバック | 障害が発生した場合、故障した装置を切り離して運転を続行すること |
| フェールオーバ | 障害が発生したも、他の処理装置が処理やデータを自動的に引継ぐ機能 |
| フェールセーブ | ハードウェアやソフトウェアに障害が発生した場合、システムを安全第一の状態にしようとする考え方(例:信号機トラブル⇒すべて赤にする) |
| フールプルーフ | 仕様から外れた使い方をしても、障害が発生しないようなシステムを構築しようとする考え方 |
信頼性向上のためのシステム構成
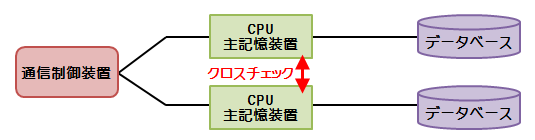
デュアルシステム
1つの処理を2台のコンピュータで処理し、処理結果を照合する
障害発生時は切り離して生きている方だけで処理をする
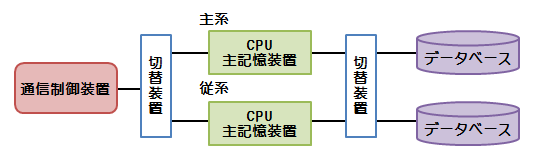
デュプレックスシステム(待機冗長化方式)
システムを2台用意し、一方を主系(現用系)、もう一方を従系(待機系)として利用し、通常は主系で処理を行う
主系に障害が発生した場合、従系に切り替えて処理を継続する
 主系と従系の扱いによる分類
主系と従系の扱いによる分類
コールドスタンバイ
主系に障害が発生した場合、待機させていた従系で主系の処理システムを起動し、処理を引き継ぐように設計されたシステム
通常、主系ではリアルタイム処理を行い、従系ではバッチ処理を行うなど、主系と従系で別の処理を行うことにより有効利用できる
ウォームスタンバイ
従系ではOSが働いているが、それ以外のプログラムは起動していない状態、主系がダウンした場合にプログラムを動かして、実行する
ホットスタンバイ
主系と従系で別の処理を行わず、従系を常に主系と同じ状態で待機させておくことで、障害が発生した場合、迅速に切り替えを行うことができる
RAID
信頼性やアクセス速度の向上を目的とした障害対策のひとつ。複数のハードディスクをまとめてひとつの装置として扱う技術
RAIDにはいくつかのレベルがあり、実際に利用されるのはRAID 0、RAID 1、RAID 5、RAID 6で、RAIDコントローラやソフトウェアによって使用できるレベルが限定されている場合が多い
| 名称 | 説明 | |
|---|---|---|
| RAID0 (ストライピング) | 特定のサイズのデータをブロック(セクタ)単位で、複数のハードディスクに分割して書き込みを行う データの書き込み時間が短縮される アクセス速度向上のための方法 | 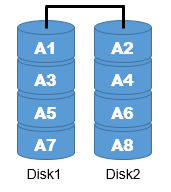 |
| RAID1 (ミラーリング) | ハードディスク自体の故障に備えて、2台のハードディスクに同じデータを書き込む 故障した場合でも、もう一方から読み出せるので信頼性が向上する | 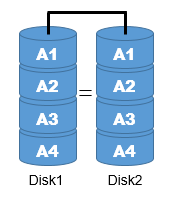 |
| RAID2 | 複数のハードディスクにデータを保存し、データのほかに、エラーの検出・訂正を行うためのコード(ハミングコード)を生成して複数のハードディスクに分散して書き込む。耐障害性は非常に高いが非実用的 | |
| RAID3 | 複数のハードディスクにデータを保存し、ビット/バイト単位でエラーの検出・訂正を行うためのパリティ情報を専門のハードディスクにも書き込む 故障した場合、パリティ情報からデータを復旧できる | 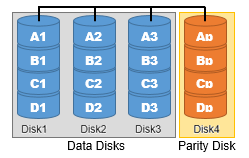 |
| RAID4 | RAID3と同様の仕組みだが、データの分割がブロック(セクタ)単位で行われる | |
| RAID5 (パリティ付きストライピング) | パリティ情報を記録するハードディスクを固定せず、総てのハードディスクに分散して記録する。データの分割がブロック(セクタ)単位で行われる 書き込み時間が短縮され、1つのハードディスクの故障には対応可 | 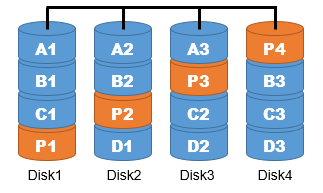 |
| RAID6 | パリティ情報を2つ生成し、すべてのハードディスクに分散して記録する 書き込み時間が短縮され、2つのハードディスクの故障にも対応可 | 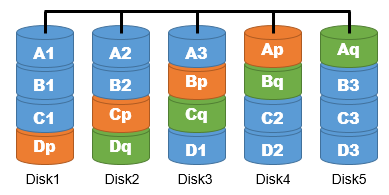 |
冗長ディスクをもたせたRAIDの特徴
| 種類 | ストライピング単位 | 誤り訂正方法 | 冗長ディスク | 備考 |
|---|---|---|---|---|
| RAID2 | ビット | ハミング符号 | 固定 | 最低5台構成、市販品なし |
| RAID3 | ビット/バイト | パリティ | 固定 | 最低3台構成、ビデオ編集用 |
| RAID4 | ブロック | パリティ | 固定 | RAID3の改善型、廃れつつある |
| RAID5 | ブロック | パリティ | 分散 | 最低3台構成、現在の主流 |
| RAID6 | ブロック | 複数パリティ | 分散 | 最低4台構成、耐障害性強化 |
NAS(ネットワークアタッチトストレージ)
●コンピュータネットワークに直接接続して使用するファイルサーバ
●TCP/IPネットワークに直接接続して使用する補助記憶装置
●専用機化した分、高速なファイルサービスを提供し、管理も容易
●RAIDを構成して冗長性、可用性を高めるのが一般的
●サーバごとに専門の磁気ディスクを接続しているシステム
●各磁気ディスクに発生している空き領域をシステム全体で有効利用
SAN(ストレージエリアネットワーク)
●外部記憶装置間および記憶装置とコンピュータの間を結ぶ高速なネットワーク
●複数のコンピュータがある場合はコンピュータ間のデータ転送も可能
●高い性能が要求されるサーバに使用
●複数のサーバが連携して一つの機能を提供する場合や、一つの大容量記憶装置を複数のサーバで共有する場合に有効
Fibre Channel(ファイバーチャネル)
コンピュータと周辺機器を結ぶためのデータ転送方式のひとつ。主に、高い性能が必要なサーバで、コンピュータ全体と外部記憶装置を接続するのに利用されている
システム評価指標
システムの性能
システムの性能指標
システムの性能を計るために、「性能テスト」が行われる。性能テストには「レスポンスタイム」「ターンアラウンドタイム」「ベンチマーク」「モニタリング」などの諸評が用いられる
レスポンスタイム
コンピュータに処理を行わせて、最初の反応が返ってくるまでの時間。「応答時間」 オンラインシステムの性能を評価するときに使用。CPUの性能や接続しているユーザ数によって変化する
ターンアラウンドタイム
コンピュータに一連の処理を行わせて、すべての処理が完了し、結果を返してくるまでに時間。バッチ処理の性能を評価するときに使用
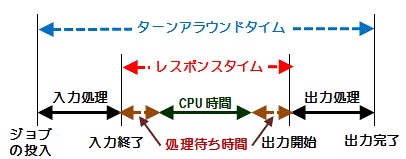
| ターンアラウンドタイムの計算式 CPU時間+入出力時間+処理待ち時間 |
ベンチマーク
システム性能を測定するためのプログラムなどを用いて、CPU稼働率やメインメモリの速度、ハードディスクの読み書き速度、レスポンスタイムなどを含む総合的なテストを行う
| TPCベンチマーク | トランザクション処理に関する性能指標の標準化を進める非営利団体(TPC)で策定されたベンチマーク。TPC-A、TPC-C、TPC-E、TPC-Hなどがある |
|---|---|
| SPEC(スペック) ベンチマーク | CPUやWebサーバなどに関する性能指標の標準化を進める非営利団体(SPEC)で策定したベンチマーク。CPUや整数演算処理の性能を評価する「SPECint(スペックイント)」やCPUの実数演算処理の性能を評価する「SPECfp(スペックエフピー)」などがある |
モニタリング
実際のシステムに性能を測定するための機器やプログラムを組み込み、どのように動作するかを計測すること
| ハードウェアモニタリング | 測定用の機器(ハードウェア)を組み込む方式 |
|---|---|
| ソフトウェアモニタリング | 想定用のプログラム(ソフトウェア)を組み込む方式 |
システムの信頼性
システムの信頼性は、システムを運用中、機能が停止することなく稼動し続けることで高くなる。評価する項目として「RASIS(レイシス)」がある
| Reliability 信頼性:故障しにくい Availability 可用性:稼働率が高い Serviceability 保守性:障害時に復旧しやすい Integrity 完全性:データに矛盾が発生しない Security 安全性:気密性が高い |
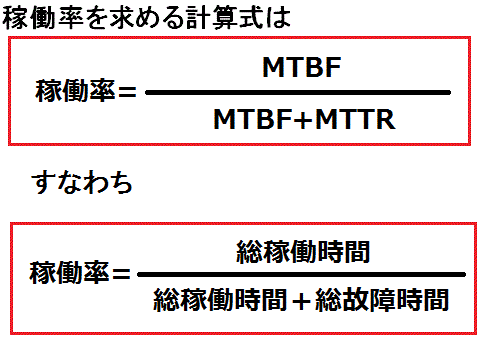
システムの稼働率
信頼性という観点からシステムを評価するために求められる指標が「稼働率」。稼働率は「平均故障間隔(MTBF:Mean Time Between Failures)」、「平均修理時間(MTTR:Mean Time to Repair)」などによって判断される
| 平均故障間隔 | MTBF | 故障から故障までに間。システムが連続して稼動している時間の平均 |
|---|---|---|
| 平均修理時間 | MTTR | 故障したときに、システムの復旧にかかる時間の平均 |
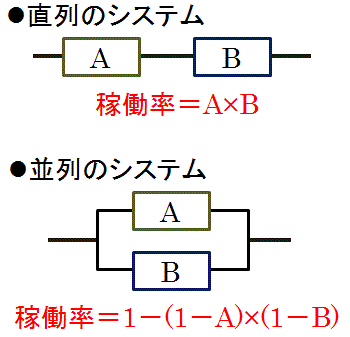
複合システムの稼働率
複数のコンピュータや機器で構成されるシステムの場合「直列システム」「並列システム」によって稼働率の求め方が違う
直列システムの稼動率
「直列システム」とは、システムを構成している装置がすべて稼動しているときだけ、稼働するシステムのこと。装置が1つでも故障した場合、システムは稼働しない
並列システムの稼働率
「並列システム」とは、どれかひとつの装置が稼働していれば、稼働するシステムのこと。システムを構成している装置がすべて故障した場合のみ、装置システムは稼働しない
3つの並列システムの稼働率
稼働率がすべてAである3つのサブシステムのいずれかX個が使用可能であればシステムとして稼働する場合の稼働率
| 状態 | 計算式 | 値 |
|---|---|---|
| 3つとも稼働 | A3 | A3 |
| 2つ稼働、1つダウン | A2×(1−A) | 3A2×(1−A) |
| 1つ稼働、2つダウン | A×(1−A)2 | 3A×(1−A)2 |
| 3つともダウン | (1−A)3 | (1−A)3 |
システムの経済性
TCO(Total Cost of Ownership)
システムの購入から破棄するまでに必要となる費用を統合したもの
●コンピュータのハードウェア、ソフトウェアの購入費用
●利用者に対する教育費用
●運用費用
●システムの保守費用
●システムのトラブルの影響による損失費用 ・・・等
キャパシティプランニング
予算や費用対策効果を考慮しつつ、必要な性能要件を満たすようなシステムを開発できるように管理するプロセスのこと
目的
| ・システムに求められる処理能力を備えた機種を、容量や台数などを考慮した うえで選定する ・将来起こる可能性のあるソフトウェアの更新や業務の変化などに対応し、 サービス品質を継続的に維持できる拡張性を備える |
活動サイクル
●モニタリング :ハードウェアの使用率、性能情報等を監視・収集する
●分析 :システムの外部・内部環境の変化を読み取り、将来に向けての性能を分析・予測する
●チューニング :既存のシステムのパフォーマンスを最適化し、求められる業務性能を達成する
●実装 :新しい機能やIT資源をシステムに追加する